Google Data Studio (GDS) includes a «Mysql Connector» to access information stored on Mysql databases.
It works great until suddenly you realize that some data is not being plotted.
In this post I will explain you why it happens and a workaround for it.
The problem
This is what I wanted to plot:
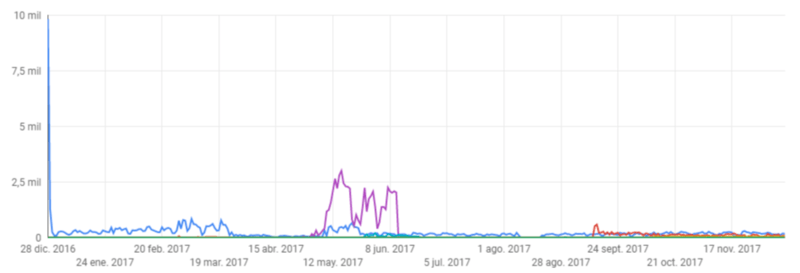
And this is what I ended up having:
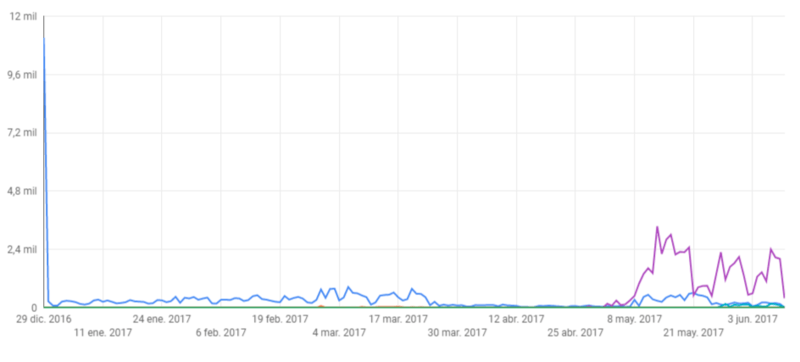
Notice that the resulting plot is a partial graph of the «desired» plot.
To figure out why this was happening, and if it was a problem related with my MySQL config (which is hosted on Siteground, and therefore I don’t have an admin user to manage it), I set up other MySQL servers on DigitalOcean with different configurations.
I even created a Google Cloud SQL Server. Please notice that, Google Cloud SQL Server doesn’t use «Mysql Connector» and uses its own Connector.
Surprisingly, the Cloud SQL Server worked fine, but no matter what Mysql config I used, it didn’t work. I ended up enabling query logging and I found out the following:
Google Data Studio always sets a 100k rows limit before doing any request.
It set by using the following query:
SET SQL_SELECT_LIMIT=100000
The server changes the limit of the Google Data Studio session. Since there is a session variable, there is no way you can override that setting on the server (or at least I haven’t found one).
It is set on both mysql and Cloud SQL connections so, why does it work on Cloud SQL Connector and doesn’t work in mysql Connector?
And the answer is pretty obvious: Cloud SQL Connector doesn’t return more that 100k rows. Take a look at the queries sent by each connector:
Mysql Connector:
SELECT Fecha, COUNT(consultado) AS qt_rH2gxrDk FROM wp_matriculas_cache AS t0 GROUP BY Fecha;
Cloud SQL Connector:
SELECT DATE_FORMAT(SUBSTR(t0.Fecha, 1, 10), '%Y%m%d') AS qt_XwMhdzDk, COUNT(consultado) AS qt_ZwMhdzDk FROM wp_matriculas_cache AS t0 GROUP BY qt_XwMhdzDk ORDER BY qt_XwMhdzDk ASC;
The MySQL query would return 165k rows (which are all the rows that exist on that table).
The Cloud SQL query would return just 615 rows.
This is because all the grouping is done in the SQL Server, instead of doing it in the Data Studio Servers, or even in the browser.
The workaround
I have found two ways to solve this problem:
- Generate the SQL query yourself (which in the end could overcrowd your data sources)
- Create calculated fields so that the query from Google Data Studio is optimized.
Route number 1 is pretty straight forward. You just have to create a new data source and input your «tuned» SQL query to the server. (Let me know in the comments if you are having any trouble with it).
For number 2, I have found that it is a trial and error thing. Depending on how you define the calculated fields, you get a different query and therefore, different results:
– TODATE(Fecha, ‘DEFAULT_DASH’, ‘%Y-%m-%d’): Returns more than 100k rows
– TODATE(t0.Fecha, ‘DEFAULT_DASH’, ‘%Y-%m-%d’): Returns 615 rows
I really don’t know what’s the difference between Fecha and t0.Fecha, because both relate to the same variable, but the SQL resulting query is indeed different.
Do you really need that many rows?
After struggling with it, I have been thinking about it and I think google limitation makes sense.
If you are using Google Data Studio, it is because you want to graph some data. Would someone really that much information on a graph? Would it make a difference?
I can’t imagine in what kind of graph you will need that many rows. I think it is impossible to notice all those
Will Google remove that restriction?
Since human eye won’t notice that much information on a graph, Google wants all the calculations to be performed on the SQL server and not on Google Data Studio or the visitor browser, which I think makes sense.
I think Google won’t remove that restriction in the future but probably the MySQL Connector will optimize queries itself, the way Google Cloud SQL Connector does and there will be not need for workarounds.
The problem that we’re running into is that we have ~200,000 rows of data to plot (but we will present it in a filtered view – the user can select which one of the categories they want to look at – to be able to give the user the ability to select any of these categories requires all 200,000 rows. Shame that this isn’t supported.